

In this article, we present our toolkit to migrate code from pandas 1 to pandas 2. Additional the reader learns about the risk of introducing bugs by dependency upgrades.
Language English
as this is a specialized issue in software development.
Breaking changes in libraries
Libraries can not always maintain their interface. Usually an increase of the major version number indicates potential breaking changes in the libraries interface. One example is the famous python library pandas. This got a backwards incompatible API changes with version 2.0.0.
If one decides to upgrade an dependencies in an existing code base, one will encounter these breaking changes in the API. Usually this boils down to 3 scenarios:
- Easy-Going: One is not effected by a breaking change. This is the best-case scenario and might be true for 90% of your code base. Be aware that you can not know for sure if everything still runs, because you are in this scenario or in „Bloody-Hell“.
- Fix-Needed: You get an error message, when running your code. Based on this, you can track, the problematic line of code and fix it. This might take a few hours, but besides the additional development effort, situation is under control and the code behaves in the same way as with the original.
- Bloody-Hell: This looks like we are in the Easy-Going scenario, but after some months we realize that there was a subtle change in behavior, which under some circumstances, causes a major production incident. Because we can not relate the production incident anymore to the dependency upgrade we performed months ago, a stressful and expensive work period starts until the root cause is found to be a breaking change in a dependency.
As an example for a potential problematic change, we can find for instance
This means, that under some circumstances, we got the original DataFrame back from the loc/iloc method in pandas version 1.5.3, but in pandas version 2.0.0 we get a shallow copy back. This is a great candidate for navigating your code into „Bloody-Hell“.
Hence, the demand rises for a save way to migrate code from pandas 1 to pandas 2.
Why upgrading requirements at all?
Often code is not maintained at all. In a very few cases, this might be reasonable, but in the vast majority of cases, we strongly dis-recommend you from doing so.
The requirement for maintainability arises from the interfaces your code uses. Each interface brings a few risks with it:
- It might get deprecated and needs to be updated.
- It can get the target of a cyberattack.
- New legal requirements require modifications.
If you start updating your dependencies and doing other maintenance work (like expanding unittests) on your code, as soon as you get a new requirement you can not deliver that fast and with high quality. This might lead you to missing deadlines or business opportunities.
If a code stays unmaintained for years, you get more and more dependencies to be upgraded (and most likely depending on each other), which increases the complexity of the problem. At a certain point, you will even get problems to find developers, familiar with the technologies used in this code.
So keep your dependencies maintained and updated, while your code is operating. This keeps you flexible concerning new demands (legal, business, interfaces) and reduces the business risk of losing control of this code.
So having this in mind, we will be eager already to migrate our code from pandas 1 to pandas 2. But there are also a few specific reasons in case of pandas.
Advantages of upgrading from pandas 1 to pandas 2
As can be seen in different benchmarks, pandas 2 gained a significant amount of speed for string and NAN operations, using the pyarrow instead of the numpy backend. Here is an overview of early benchmarks:
- Medium: Pandas 2.0 vs Pandas 1.3 — Performance Comparison
- Datacamp: Pandas 2.0: What’s New and Top Tips
So there are good reasons to migrate code from pandas 1 to pandas 2. But also the demand arises for a risk controlled way of doing so.
How to migrate code from pandas 1 to pandas 2
Theoretically, unittests should be able to detect all issues with the new dependency. This is however only true, if they were perfectly written and usually developers test their code and not the functionality of their dependencies.
Also, a manual line-by-line comparison is impossible for large codes.
Our approach from Algorithmus Schmiede is, to execute the code (or its unittests) in a debugger parallely in 2 environments: the original one and the upgraded one. After every line of code, a comparison is performed between all pandas objects.
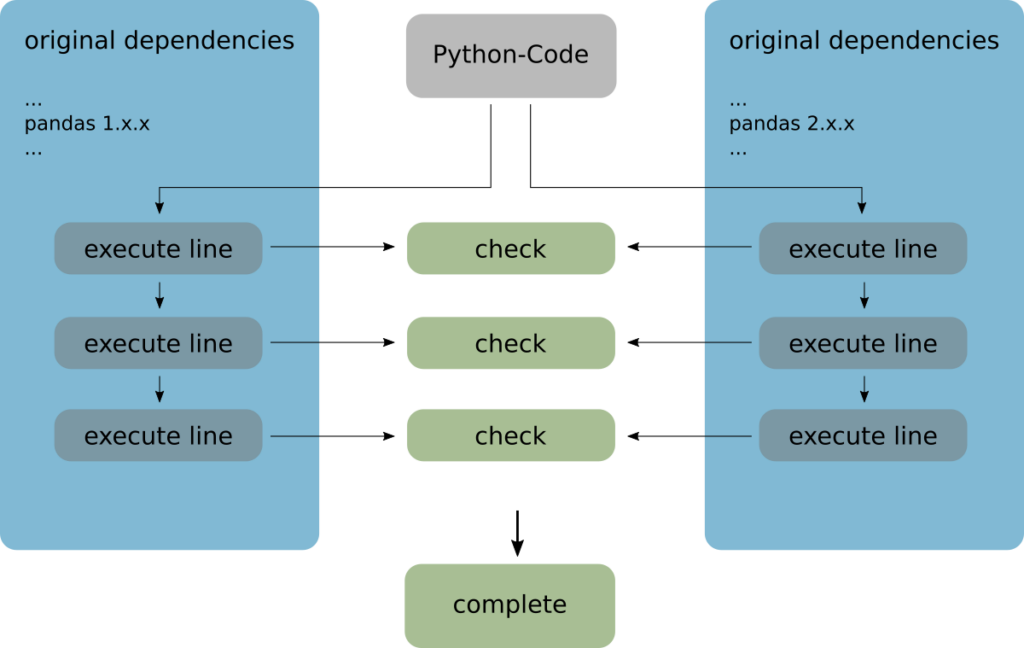
In this way, we can guarantee, that there is no unexpected behavior introduced by the new version of a dependency.
Get support and migrate code from pandas 1 to pandas 2
- You need help, upgrading a dependency for a complex python code?
- You want to migrate your code from pandas 1 to pandas 2?
- You want to ensure compatibility of your code with the updated requirement?
We can support you with our tools or even perform the migration for you.
Just reach out to us and start getting this issue solved …
